
Sound - for audio playback¶
Audio playback is handled by the Sound class. PsychoPy® currently
supports a choice of sound engines: PTB, pyo, sounddevice or pygame. You
can select which will be used via the audioLib
preference. sound.Sound() will then refer to one of the following backends:
This preference can be set on a per-experiment basis by importing preferences, and setting the audioLib option to use. Audio playback backends vary in performance due to all sorts of factors. Based on testing done by the PsychoPy® team and reports from users, their performance can be summarized as follows:
The PTB library has by far the lowest latencies and is strongly recommended (requires 64 bit Python 3.6+)
The pyo library is, in theory, the highest performer, but in practice it has often had issues (at least on MacOS) with crashes and freezing of experiments, or causing them not to finish properly. If those issues aren’t affecting your studies then this could be the one for you.
The sounddevice library has performance that appears to be good (although this might be less so in cases where you have complex rendering being done as well because it operates from the same computer core as the main experiment code). It’s newer than pyo and so more prone to bugs and we haven’t yet added microphone support to record your participants.
The pygame backend is the oldest and should work without errors, but has the least good performance. Use it if latencies for your audio don’t matter.
Sounds are actually generated by a variety of classes, depending on which “backend” you use (like pyo or sounddevice) and these different backends can have slightly different attributes, as below. The user should typically do:
from psychopy.sound import Sound
The class that gets imported will then be an alias of one of the Sound Classes described below.
PTB audio latency¶
PTB brings a number of advantages in terms of latency.
The first is that is has been designed specifically with low-latency playback in mind (rather than, say, on-the-fly mixing and filtering capabilities). Mario Kleiner has worked very hard get the best out of the drivers available on each operating system and, as a result, with the most aggressive low-latency settings you can get a sound to play in “immediate” mode with typically in the region of 5ms lag and maybe 1ms precision. That’s pretty good compared to the other options that have a lag of 20ms upwards and several ms variability.
BUT, on top of that, PTB allows you to preschedule your sound to occur at a particular point in time (e.g. when the trigger is due to be sent or when the screen is due to flip) and the PTB engine will then prepare all the buffers ready to go and will also account for the known latencies in the card. With this method the PTB engine is capable of sub-ms precision and even sub-ms lag!
Of course, capable doesn’t mean it’s happening in your case. It can depend on many things about the local operating system and hardware. You should test it yourself for your kit, but here is an example of a standard Win10 box using built-in audio (not a fancy audio card):
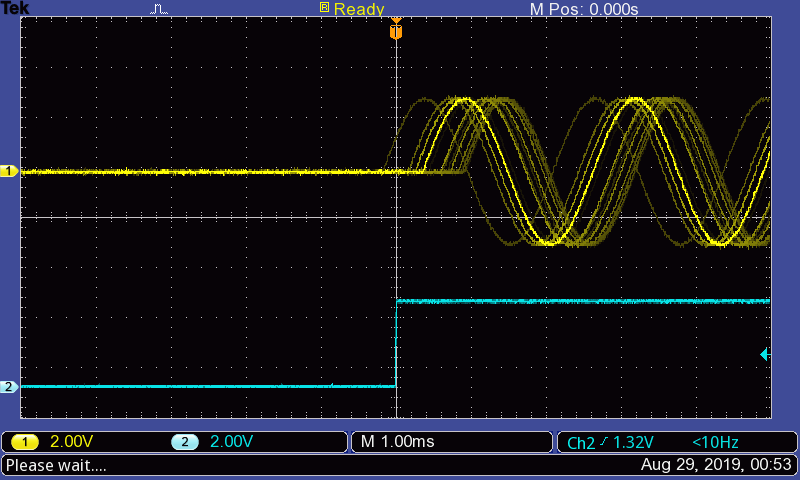
Fig. 47 Sub-ms audio timing with standard audio on Win10. Yellow trace is a 440 Hz tone played at 48 kHz with PTB engine. Cyan trace is the trigger (from a Labjack output). Gridlines are set to 1 ms.¶
Preschedule your sound¶
The most precise way to use the PTB audio backend is to preschedule the playing of a sound. By doing this PTB can actually take into account both the time taken to load the sound (it will preload ready) and also the time taken by the hardware to start playing it.
To do this you can call play() with an argument called when. The when argument needs to be in the PsychToolBox clock timebase which can be accessed by using psychtoolbox.GetSecs() if you want to play sound at an arbitrary time (not in sync with a window flip)
For instance:
import psychtoolbox as ptb
from psychopy import sound
mySound = sound.Sound('A')
now = ptb.GetSecs()
mySound.play(when=now+0.5) # play in EXACTLY 0.5s
or using Window.getFutureFlipTime(clock=’ptb’) if you want a synchronized time:
import psychtoolbox as ptb
from psychopy import sound, visual
mySound = sound.Sound('A')
win = visual.Window()
win.flip()
nextFlip = win.getFutureFlipTime(clock='ptb')
mySound.play(when=nextFlip) # sync with screen refresh
The precision of that timing is still dependent on the PTB Audio Latency Modes and can obviously not work if the delay before the requested time is not long enough for the requested mode (e.g. if you request that the sound starts on the next refresh but set the latency mode to be 0 (which has a lag of around 300 ms) then the timing will be very poor.
PTB Audio Latency Modes¶
When using the PTB backend you get the option to choose the Latency Mode,
referred to in PsychToolBox as the reqlatencyclass, and can be set in
psychopy.hardware.speaker.SpeakerDevice
PsychoPy® uses Mode 3 in as a default, assuming that you want low latency and you don’t care if other applications can’t play sound at the same time (don’t listen to iTunes while running your study!)
The modes are as follows:
- 0 : Latency not important
For when it really doesn’t matter. Latency can easily be in the region of 300ms! The advantage of this move is that it will always work and always play a sound, whatever the format of the existing sounds that have been played (with 2, 3, 4 you can obtain low latency but the sampling rate must be the same throughout the experiment).
- 1 : Share low-latency access
Tries to use a low-latency setup in combination with other applications. Latency usually isn’t very good and in MS Windows the sound you play must be the same sample rate as any other application that is using the sound system (which means you usually get restricted to exactly 48000 instead of 44100).
- 2 : Exclusive mode low-latency
Takes control of the audio device you’re using and dominates it. That can cause some problems for other apps if they’re trying to play sounds at the same time.
- 3 : Aggressive exclusive mode
As Mode 2 but with more aggressive settings to prioritise our use of the card over all others. This is the recommended mode for most studies
- 4 : Critical mode
As Mode 3 except that, if we fail to be totally dominant, then raise an error rather than just accepting our slightly less dominant status.
PTB Devices¶
To set the output audio device to use, you can set the prefs.hardware[‘audioDevice’] setting. To determine the set of available devices, you can do for example:
from pprint import pprint
import psychtoolbox.audio
pprint(psychtoolbox.audio.get_devices())
Sound Classes¶
PTB Sound¶
- class psychopy.sound.backend_ptb.SoundPTB(value='C', secs=0.5, octave=4, stereo=-1, volume=1.0, loops=0, sampleRate=None, blockSize=128, preBuffer=-1, hamming=True, startTime=0, stopTime=-1, name='', autoLog=True, syncToWin=None, speaker=None)[source]¶
Play a variety of sounds using the new PsychPortAudio library
- Parameters:
value – note name (“C”,”Bfl”), filename or frequency (Hz)
secs – duration (for synthesised tones)
octave – which octave to use for note names (4 is middle)
stereo – -1 (auto), True or False to force sounds to stereo or mono
volume – float 0-1
loops – number of loops to play (-1=forever, 0=single repeat)
sampleRate – sample rate for synthesized tones
blockSize – the size of the buffer on the sound card (small for low latency, large for stability)
preBuffer – integer to control streaming/buffering - -1 means store all - 0 (no buffer) means stream from disk - potentially we could buffer a few secs(!?)
hamming – boolean (default True) to indicate if the sound should be apodized (i.e., the onset and offset smoothly ramped up from down to zero). The function apodize uses a Hanning window, but arguments named ‘hamming’ are preserved so that existing code is not broken by the change from Hamming to Hanning internally. Not applied to sounds from files.
startTime – for sound files this controls the start of snippet
stopTime – for sound files this controls the end of snippet
name – string for logging purposes
autoLog – whether to automatically log every change
syncToWin – if you want start/stop to sync with win flips add this
- _EOS(reset=True, log=True)[source]¶
Function called on End Of Stream
- _channelCheck(array)[source]¶
Checks whether stream has fewer channels than data. If True, ValueError
- _checkPlaybackFinished()[source]¶
Checks whether playback has finished by looking up the status.
- property isFinished¶
True if the audio playback has completed.
- property isPlaying¶
True if the audio playback is ongoing.
- pause(log=True)[source]¶
Stops the sound without reset, so that play will continue from here if needed
- play(loops=None, when=None, log=True)[source]¶
Start the sound playing.
Calling this after the sound has finished playing will restart the sound.
- setSound(value, secs=0.5, octave=4, hamming=None, log=True)[source]¶
Set the sound to be played.
Often this is not needed by the user - it is called implicitly during initialisation.
- Parameters:
- value: can be a number, string or an array:
If it’s a number between 37 and 32767 then a tone will be generated at that frequency in Hz.
It could be a string for a note (‘A’, ‘Bfl’, ‘B’, ‘C’, ‘Csh’. …). Then you may want to specify which octave.
Or a string could represent a filename in the current location, or mediaLocation, or a full path combo
Or by giving an Nx2 numpy array of floats (-1:1) you can specify the sound yourself as a waveform
- secs: duration (only relevant if the value is a note name or
a frequency value)
- octave: is only relevant if the value is a note name.
Middle octave of a piano is 4. Most computers won’t output sounds in the bottom octave (1) and the top octave (8) is generally painful
- stop(reset=True, log=True)[source]¶
Stop the sound and return to beginning
- property stream¶
Read-only property returns the stream on which the sound will be played
- property track¶
The track on the master stream to which we belong